List of ICML GAN Papers
Posted on 07/08/2018 by Jakub Langr
Posted in technical
In all seriousness, however, I do respect greatly all the amazing work that the researchers at ICML have presented. I would not be capable of anywhere near their level of work so kudos to them for pushing the field forward!
ICML overall was an awesome experience. But this piece is not going to be about my thoughts, impressions or experiences. The industry of slowly slipping into academic conferences I thought I might take it one step further and present what are the most interesting results for the practitioners perspective that came up at this conference.
This means I will be discounting some of the academic contributions if I do not see how they could apply to someone whose ultimate goal is not first and foremost to publish. This also means that I will be using more accessible language and will not go into any given paper. I will try to present this in a more accessible way, which also means I will here and there contribute some opinions and thoughts that some of you may disagree with. My hope here is that this will be useful especially to the newcomers to the field to give them some context from the about 50 papers that I have read in preparation for this conference.
Very frequently the explanations will be quick and dirty as exemplified by the fact that not every single paper is strictly speaking a generative adversarial network. So here it goes.
As part of my training budget at Mudano, I chose to go to ICML, a top 3 conference in Machine Learning. It was a very enriching and unique experience. But in order to get the most out of the conference I decided to keep track of most papers I have encountered. These are then presented chronologically as they appeared in the conference. I'm not including Saturday and Sunday which were mostly about workshops. [1]
Wednesday 11th
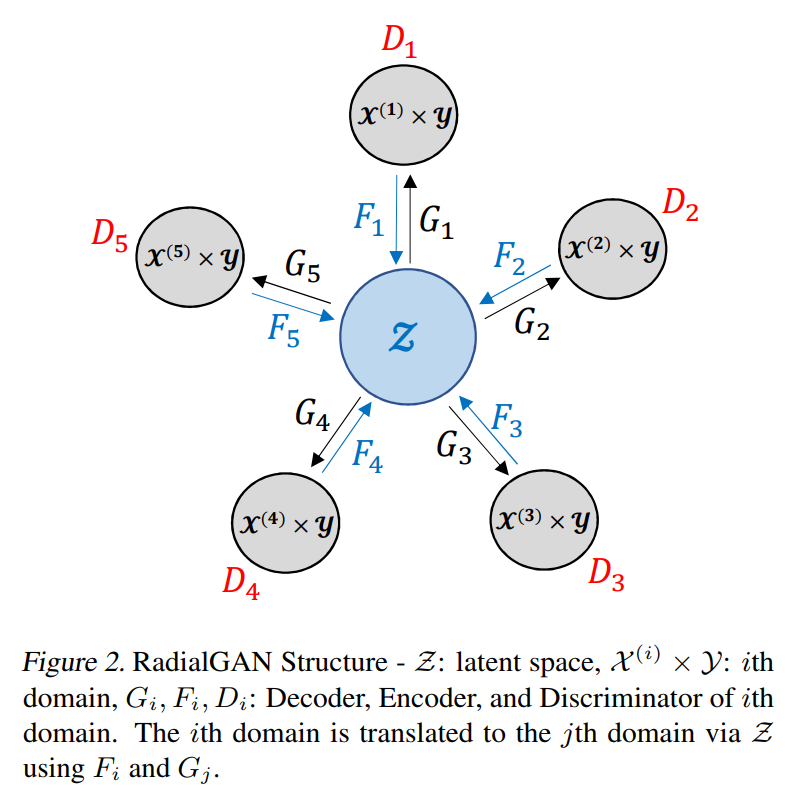
RadialGAN
The promise of GANs has always partially lied in semi-supervised learning and data augmentation. This work basically allows us to leverage multiple datasets from several sources to typically obtain better performance, even if some of the datasets are not of high quality or related to the task at hand. This is done by first translating the dataset into some shared latent space and then translating this space back to the target domain for the task at hand.
My thoughts: I really like this paper. Potentially very useful in the industry. Also very clear presentation. One of my colleagues was really excited by the potential. This paper really can be a game-changer, if it applies to your problem.
Discovering Interpretable Representations for Both Deep Generative and Discriminative Models
This is basically a human-in-the-loop Active Learning way of making sure we can interpret the latent space most (human)-meaningfully. Potentially decreases the accuracy, but allows us to say which dimensions of the latent space are affecting what properties.
My thoughts: Potentially interesting, because frequently figuring out how the latent space translates to the generated samples is non-trivial. Presentation was not very clear.
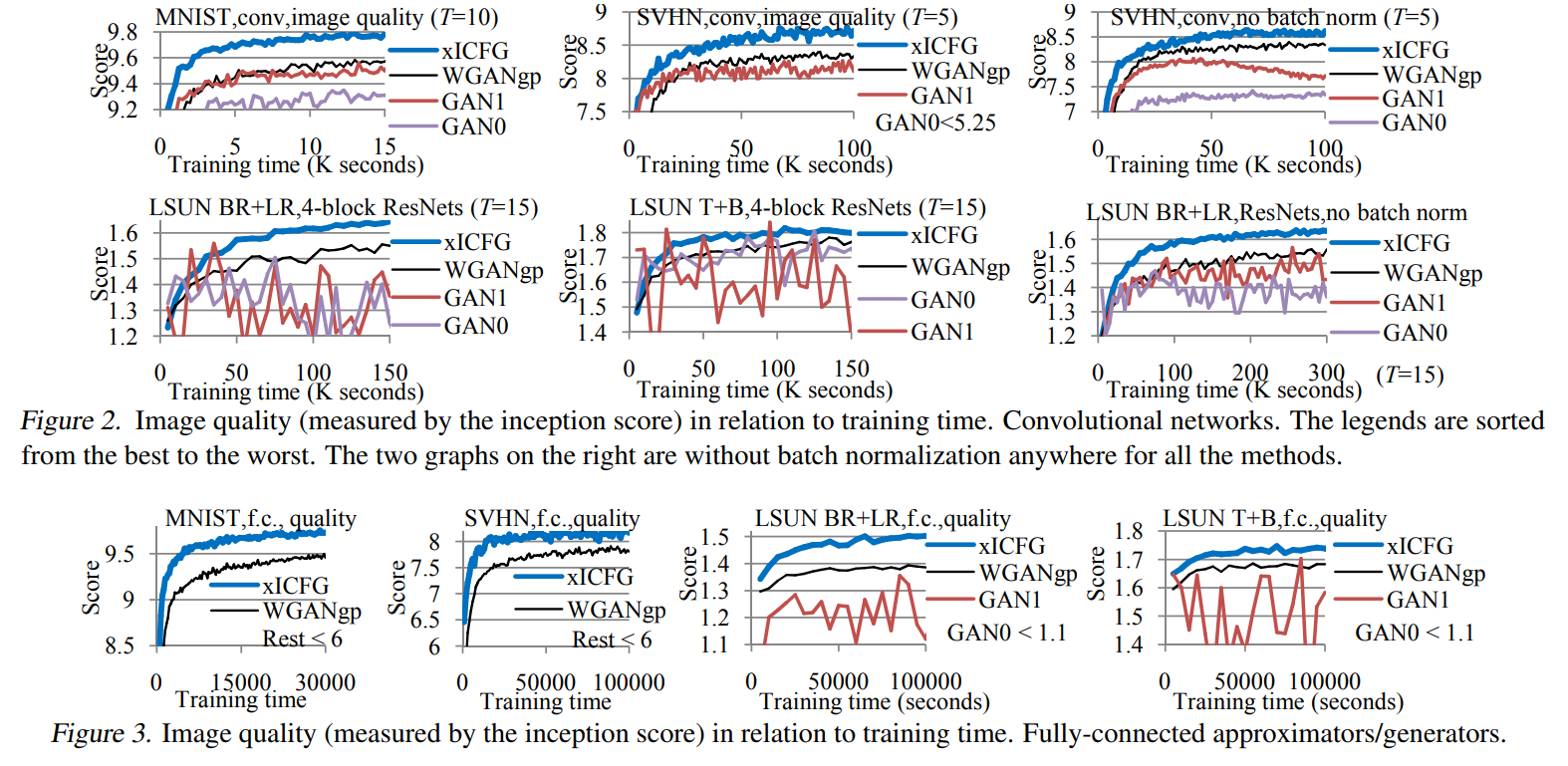
Which Training Methods for GANs do actually Converge?
In this paper, Lars et al. present a way--starting from a toy example--to impose a specific class of gradient penalties on the GANs throughout training. They show results matching state of the art (SOTA) [2] even with older architectures. The authors furthermore demonstrate some interesting properties in the local stability around the Nash Equilibrium of the GAN. Code is also available in the link above.
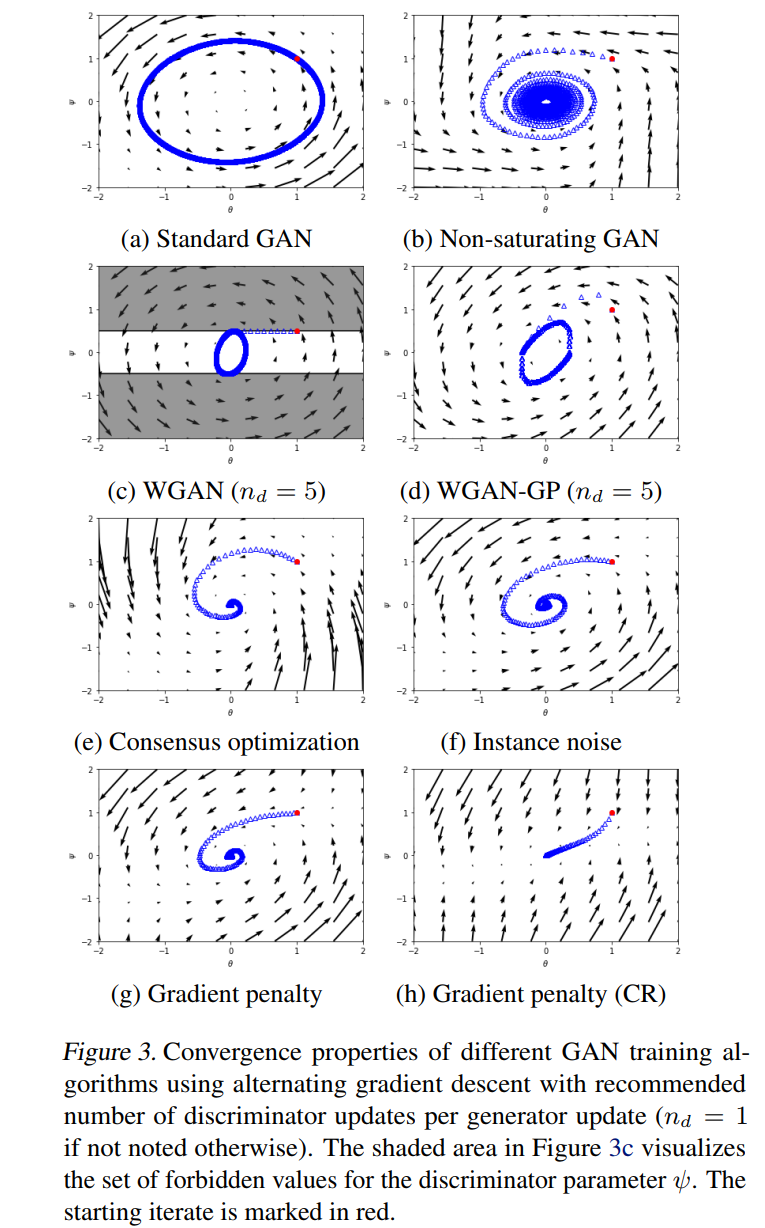
My thoughts: Quite an impressive feat. This technique is quite complicated, but taking the time to understand is probably worth the time. Others have looked at similar ideas. But in this case, results really speak for themselves. PGGAN-quality results without progressive growing!
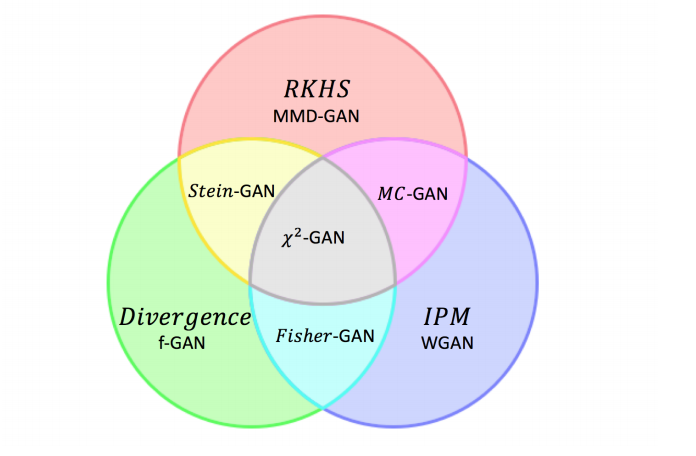
Chi-square Generative Adversarial Network
This work connects so far three disconnected approaches to GANs--see the picture below.
My thoughts: My take on this is work is that this is probably an important piece of theory, but the use for practitioners is likely somewhat limited. Fully explaining what Moment Matching Discrepancy is beyond the scope of this piece. We can simplify IPM to be simply distilling the difference of generated and real distribution to Earth Mover's distance and f-GANs are based on f-divergences.
{kind=link}
Seems a bit too convoluted for practitioners.
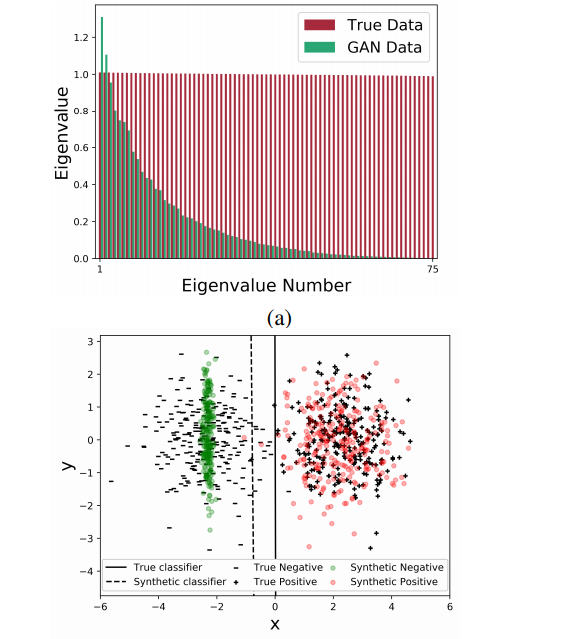
A Classification-Based Study of Covariate Shift in GAN Distributions
This is a cool study of detecting mode collapse. This generally makes sense especially for academics trying to detect problems with training. This means we can now finally start talking about the effect of these missing modes and gaps.
My thoughts: I think there's loads of value in having a consistent / unique benchmark for evaluating training quality. But there are metrics that I've liked better, but this could probably be used as an ensemble.
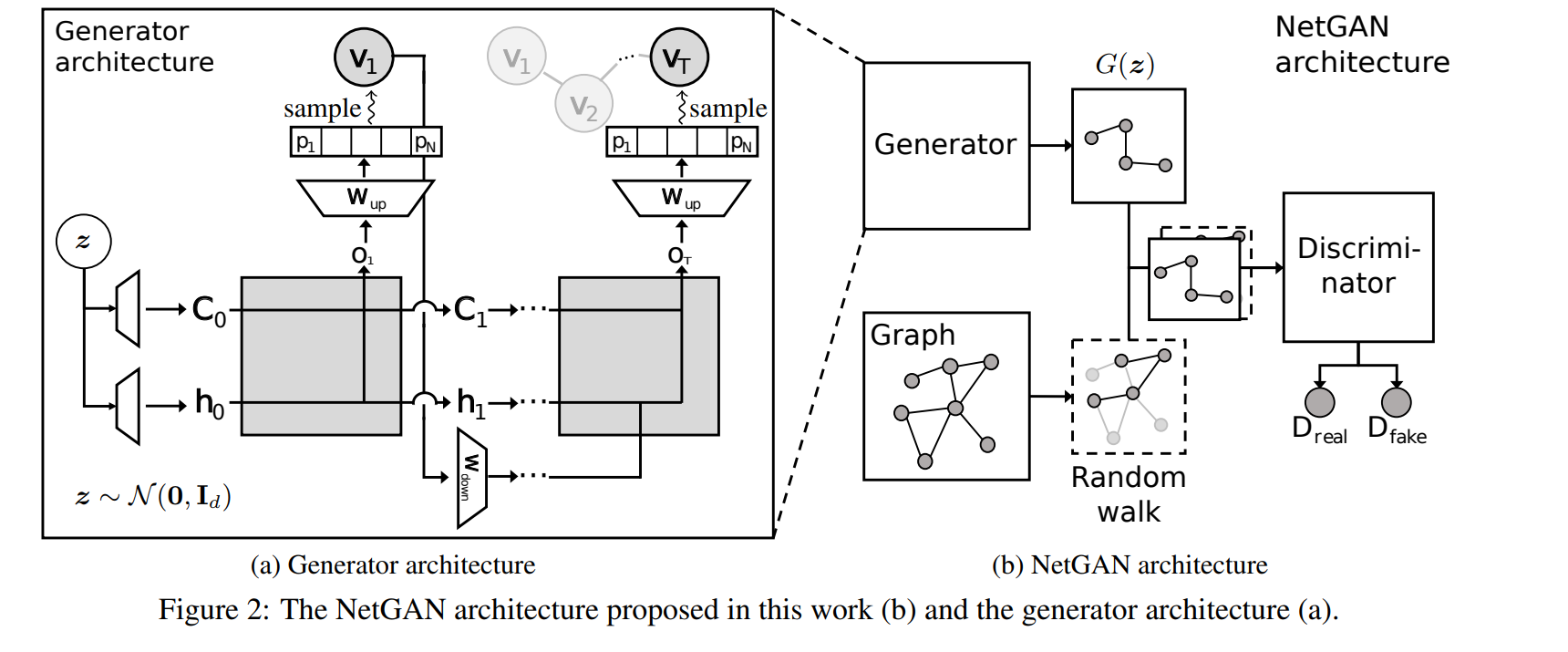
NetGAN: Generating Graphs via Random Walks
Thoughts: Generally interesting work showing that GANs can be applied to generate even graphs that are for many reasons more complicated. Achieves state of the art according to link prediction accuracy.
Thursday 12th
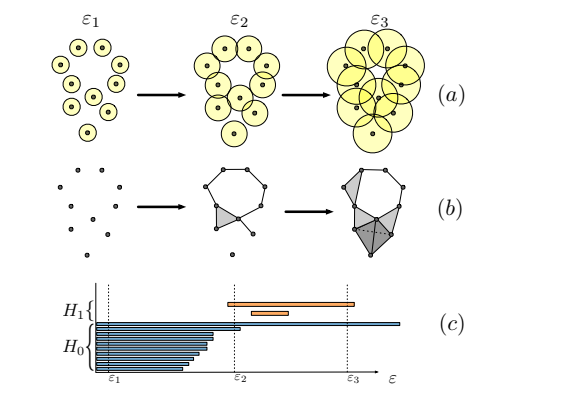
Geometry Score: A Method For Comparing Generative Adversarial Networks
This work shows that using topological analysis we can construct a general metric to evaluate how much of the original dataset we have managed to cover. Using an approximation, we can calculate how much of the diversity is in our generated dataset.
Thoughts: I am actually really excited by this work as it allows us to evaluate GANs in any domain and inspect it for mode collapse. So far, generic evaluation methods have been completely missing. Maybe we will even see a measure of quality one day.
Optimizing the Latent Space of Generative Networks
This paper deviates from the typical GAN set up, but sets out to create a model that would be able to generate better samples. Here, we focus on the issue of mode collapse and generating samples that are not the same, but are similar enough.
Thoughts: I have a bit of mixed feelings about the paper. On one hand, I think that the presentation was surprisingly opinionated--unusual for academics--and I did not agree with a lot of the statements. On the other hand, the informal poster discussion was actually really good and informative. In this discussion, one of the researchers made an interesting point that mode collapse is the reasons why GANs work. That's a fascinating assertion and I would love to see whether that is true. The funny thing about this paper is that when I was researching it, I found out that it narrowly got rejected from ICLR so the authors republished to ICML.

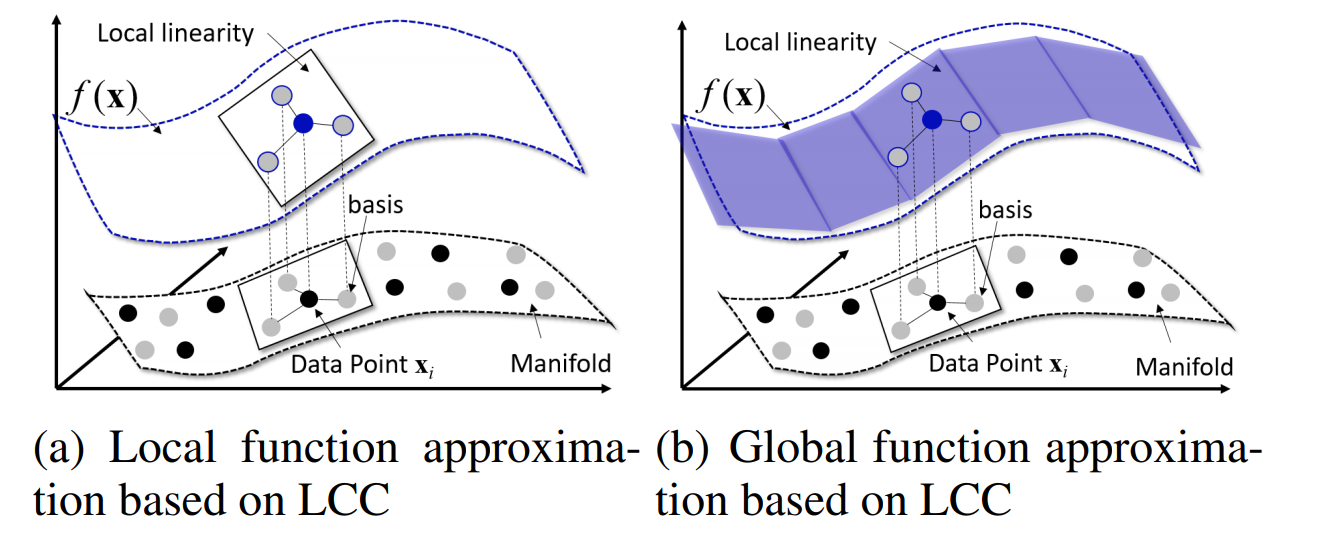
Adversarial Learning with Local Coordinate Coding
This paper attempts to solve a similar problem as the previous paper but making the latent space more complex. The presentation was not very clear, but the gist is exploring the manifold assumption--which states that there exists a mapping from some low dimensional latent space onto the complex manifold (e.g. images). All GANs ultimately rely on this assumption, but if you think about this mapping, it seems odd that you could represent all the images from such a low space. For some reason, this paper does not compare to the state of the art methods.
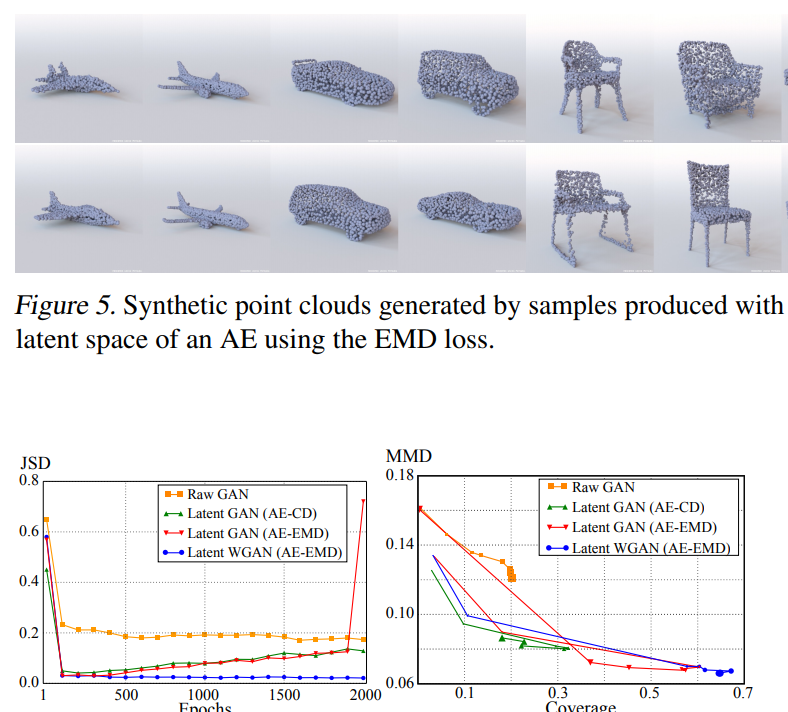
Learning Representations and Generative Models for 3D Point Clouds
Who does not love 3D point clouds? So awesome. In this paper, the authors create a more powerful model to generate 3D point clouds of generic objects. While there is still a lot of work to be done, it looks awesome.
Theoretical Analysis of Image-to-Image Translation with Adversarial Learning
This paper analyzes the paired translation GANs and says that essentially there is two components to the loss for paired image-to-image translation. The identity loss that ensures the image is correct and then the adversarial loss, which ensures the image is sharp.
Thoughts: Interesting theoretical work, but probably not for practitioners just yet. Also there are no pictures in the paper so here's at least a blurry one (sorry!) from the poster session.

Composite Functional Gradient Learning of Generative Adversarial Models
Thoughts: This paper introduces a more complicated training regime that seems to be theoretically supported, but then goes and creates an approximate version that adds an if statement to the training procedure, which to me smells of ad-hoc. The results surpass state of the art, but I generally like methods that add less complexity.
Tempered Adversarial Networks
The high level idea behind this paper is interesting. Similar to PGGAN, authors think that the problem that GANs are presented with from the outset is a bit too hard. So instead, the authors create a network that deforms the images a bit so that the generator has an easier job. A decayed version of this, beats the state of the art.
Improved Training of Generative Adversarial Networks using Representative Features
This paper basically concatenates an autoencoded version of the generated image that gets passed to the discriminator as help. The author’s poster was incredibly clear in describing the architecture, but unfortunately, the pictures seem to have disappeared from my phone.
Their results are better than the state of the art, but not by much, so I am not sure whether it is actually that much of a breakthrough.

A Two-Step Computation of the Exact GAN Wasserstein Distance
This paper introduced linear programming to compute the exact Wasserstein distance tractably and then use that to improve the training. The problem with the Wasserstein distance is that when you think about how combinatorially complex it is for even simple point clouds, computing the exact distance seems pretty complicated. This paper achieves that and beats state of the art.
The dataset that this paper uses as benchmarks are both quite simple and limited (MNIST, CIFAR-10), so I would love to see how well this method does on e.g. Celeb-A HQ or IMAGENET-1000.
Is Generator Conditioning Causally Related to GAN Performance?
Some as with some other papers, I have read this paper ages ago, but the authors did a great job of succinctly summarizing the results, especially for the poster. Basically, they use Jacobian clamping to curb the Generator updates and therefore achieve a much more stable training. The performance is not substantially improved, but the increase in stability is worth it.
As a practitioner, if you have problems with GAN stability, this is the paper to try.
GAIN: Missing Data Imputation using Generative Adversarial Nets
This paper is probably one of the most interesting papers for practitioners, because it deals with a problem that a lot of us encounter--missing data. It creates a GAN-setup with a hint mechanism to basically smartly infer the missing values to match the distribution. We know GANs are good at creating synthetic distributions. The hint mechanism is necessary, because the problem for the discriminator is too hard--there are many combinatorially valid permutations of partially missing / real data to make this intractable.
I have already pitched this paper to some of my colleagues. Enough said.
Black-box Adversarial Attacks with Limited Queries and Information
This is one of the few realistic adversarial attack papers. Technically no GAN / generative modelling involved--other than the perturbations I guess--but very interesting, realistic ways of doing adversarial attacks.
I still don't think Deep Learning models are widespread enough and that there's enough trust in them for this to cause any real harm, but this paper engages with the real issues.
First Order Generative Adversarial Networks
The idea behind this paper is that in a case of gradient penalties (such as WGAN-GP) rather than optimizing for the WGAN loss and then adding the penalty, you optimize for the loss with the penalty directly. Authors say that there are pathological cases when optimizing for loss and then adding the penalty makes the generated distribution itself less close to the target distribution. There were some informal grilling (not by me) / proofs of this around the poster but I won't hold the authors to it, haha.
Synthesizing Programs for Images using Reinforced Adversarial Learning
Here, I am not linking the paper itself but rather an excellent blog post by DeepMind, which does a great job of explaining this paper. TL;DR: GAN to generate brushstrokes using Photoshop-like API does a good job of learning to arbitrarily draw.
MAGAN: Aligning Biological Manifolds
Okay, so here I am now pretty sure that MAGAN stands for Manifold Alignment GAN (though never stated in the presentation), but when I first saw it being presented by an American, I thought it had some political connotations, haha. This GAN basically ensures that we align two manifolds always with the same correspondence (rather than stochastically as is the case with other algorithms) by adding in a correspondence loss.
Interesting tidbit, in a "question" after the talk someone alleged that there already was a paper at last NIPS doing exactly this. Author was unaware of this paper. Your thoughts?
Adversarial Time-to-Event Modeling
In a similar domain as the GAIN paper, except now focused on time-series and basically getting a better probability distribution (basically being able to infer it automagically) for time distribution of certain events--such as complications in hospital settings.
Potentially very useful for people working with time-series.
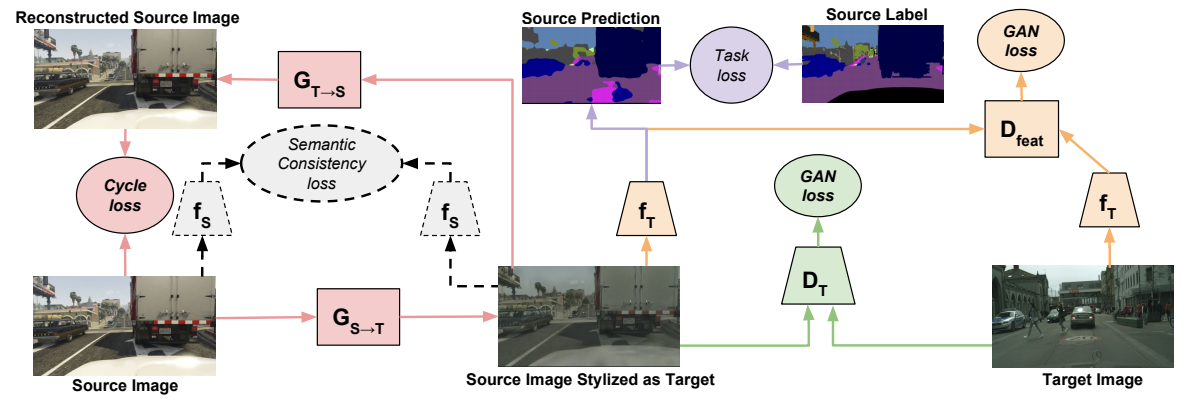
CyCADA: Cycle-Consistent Adversarial Domain Adaptation
This paper deals with an issue that loads of practitioners find out over and over a-GAN: our models do not generalize (excuse the joke). Frequently, you may take a model that was e.g. trained on ImageNet, deploy it and see that it does very poorly. Just because the real world is a lot more complicated than ImageNet even if we only care about the ImageNet classes. CyCADA extends CycleGAN to basically be able to do domain to domain translation with correct semantics and thereby potentially enabling building e.g. self-driving cars in safe, scalable computer-generated environment and then translating the ML system into the real world.
Really interesting! Will definitely try.
Autoregressive Quantile Networks for Generative Modeling
So technically there is nothing GAN in this paper. "Just" autoregressive models, but they achieve results comparable to the state of the art in GANs. Really impressive work, but as with every autoregressive model this setup, will have trouble scaling. After the talk, authors proposed using an autoencoder to scale this up, but that brings a whole set of other challenges.
Interesting approach, but similar (though lower quality) works have been presented and have never gotten over the 32x32 pixel limit, which is also the case here. Until that is solved (and many have tried), not so sure whether this is really scalable; also note GANs are already at 1024x1024.
Mixed batches and symmetric discriminators for GAN training
Unlike regular GAN, this paper uses mixed batches of real and synthetic data to make the discriminator even better. As the authors say in the summary "a simple architectural trick makes it possible to provably recover all functions of the batch as an unordered set".
I genuinely love the paper, because it is an elegant idea and the summary actually summarizes the paper. Whether or not this become the dominant framework is yet to be seen, but I think the way the authors reference other architectures is a bit odd (they got them all from one paper).
JointGAN: Multi-Domain Joint Distribution Learning with Generative Adversarial Nets
Here, the authors have an architecture similar to CycleGAN, but rather than to infer solely the conditional distributions, it jointly learns the marginal probability distributions for each domain. We start from noise for generation of X and then condition on the X in generation of Y from the marginal.
I have found the presentation to be a bit unclear, but the results seem really interesting. The text generation seems really impressive, but then the authors said this was actually done by an autoencoder from a latent space that the GAN generated.
Augmented CycleGAN: Learning Many-to-Many Mappings from Unpaired Data
This is a really neat extension to CycleGAN in its standard form by injecting latent space during the first and the second generation. Recall that Cycle-consistency loss is measured as diff(X1, X2), where X1 -> Y -> X2. Basically the authors give us extra variables to use to create samples that have certain qualities. For example, if we have an outline of a shoe in the Y domain we can generate a sample in the X domain, where the same type of shoe is blue or orange or whatever we choose.
If you like CycleGAN, but want more control over the translation, you will love this.
On the Limitations of First-Order Approximation in GAN Dynamics
This is a pure theory paper that just reasons mostly on the level of simple examples. The key takeaway is an explanation why multiple discriminator updates probably make sense. This paper takes it to the extreme and shows good convergence properties in the case of optimal discriminator. But other than that, probably not of interest to practitioners at the moment.
So that wraps up ICML for the generative adversarial networks papers. I hope that you found this useful and if you'd like me to produce were from NIPS where I am going in December (or a write up on how to get the most out of a conference) please let me know.
Thank you Karen Trippler and Mihai Ermaliuc for your thoughts and comments!
Want to join the conversation? See more at jakublangr.com or tweet @langrjakub! I am also writing a book about Generative Adversarial Networks, which you can check out here.
[1] I went to the reproducible machine learning one which should hopefully be at least somewhat familiar to most machine learning practitioners. But if there is interest I can read that up too.
[2] SOTA just means beating the previous best academic result at this benchmark. For instance, DAWNBench is the current repository of state of the art for time to get to 93% classification accuracy on Imagenet.
GANs & applied ML @ ICLR 2019
TL;DR: at the bottom. I have just return
AI Gets Creative Thanks To GANs Innovations
For an Artificial Intelligence (AI) professional, or data scientist, the barrage of AI-marketing can evoke very different feelings than for a general audience. For one thing, the AI indu
List of ICML GAN Papers
In all seriousness, however, I do respect greatly all the amazing work that the researchers at ICML have presented. I would not be capable of anywhere near their level of work so kudos to them
Comments