GANs & applied ML @ ICLR 2019
Posted on 11/05/2019 by Jakub Langr
Posted in technical

TL;DR: at the bottom.
I have just returned from International Conference on Learning Representations (ICLR) 2019 in New Orleans and what a fruitful year that was on GAN papers. In the first section, I discuss the themes featuring papers on image synthesis (BigGAN), audio (WaveGAN), feature selection (KnockoffGAN), 3D, text & tabular and many other! The second part of this article is then focused on more practical ML considerations.
Fortune favours the prepared
Before going to ICLR, I made a list of all the talks & workshops that had something that I wanted to learn. This meant a very busy Monday—where at one point four interesting workshops were running in parallel (more on the workshops in the "Applied ML" section). It also meant a busy Tuesday where the organizers put 37 GAN papers into the day. This meant starting the poster session early and finishing late. I have kept track of all this using a spreadsheet.
I have included links to all the papers I mention and there are even links to the livestreamed workshops as well as the plenary session, which also heavily featured GANs.
Generated Adversarial section
Here I want to explore the changes specifically just discussing Generative Adversarial Networks (GANs). As many have said, this is an exciting new technology that—unlike most of other ML—has only been around for less than 5 years. In the spirit of the previous ICML 2018 article, I talked to academics so you don't have to, but given the volume of the content, it is no longer possible to go through every paper, so I will just pick some main themes.

Theme 1: Image synthesis is maturing
Ian Goodfellow frequently talks of how deep learning revolutions in 2012, enabled a "Cambrian explosion" of machine learning applications. This is because in any technical field the first order of business is to make a technology work reliably and that enables a whole wealth of downstream applications.
This has somewhat happened with image synthesis. Now that BigGAN can reliably generate very diverse high-fidelity images, we can start thinking about applying it for other use-cases. One example is using BigGAN as a way to augment the existing training data (i.e. artificially increasing the number of data points by synthesizing new ones). Now even though there was another paper accepted at ICLR that showed the limitations of this technique. It seems that in this case of a balanced dataset, the GAN data augmentation has likely limited impact on the downstream task. But the sheer fact that this is a proposal that is seriously studied seems like a good sign and still leaves many data-augmentation avenues unexplored.
Another downstream task that we may care about is image synthesis with fewer labels. In the original BigGAN, we are using all labels in ImageNet to synthesize the 1,000 types of objects. However in another ICLR paper, we can see equally high quality pictures with just 10% of the labels and even better results than BigGAN with just 20% by using self and semi-supervised learning.
Furthermore, ICLR featured several papers that had interesting proposals to achieve more granular control over the generated images. So now that giraffe you always wanted in your photos instead of your ex can be just in the right spot.
I am just amazed at how quickly the field is moving that in less than 5 years since the original paper, we have managed to produce 1000 classes of 512x512 images that are realistic enough to be used in downstream applications. In the words of Károly Zsolnai-Fehér, what a time to be alive!
Theme 2: Exotic data types / applications.
Another substantial theme in this year's ICLR was the presence of more "exotic" data types and applications. I'll just go through a couple of the more interesting ones. To me, this again seems somewhat indicative of the growing maturity of GANs as a field.
- WaveGAN: is a conditional synthesis of audio using GANs using dilated convolutions and DCGAN-like architecture.
- TimbreTron: uses CycleGAN to transfer music from one instrument (domain) to music of another (domain) instrument.
- PateGAN: is a GAN to generate synthetic data with differential privacy guarantees.
- KnockoffGAN: is a way to do robust feature selection with GANs with knockoffs. Overall, this paper would be one of the more convoluted ones.
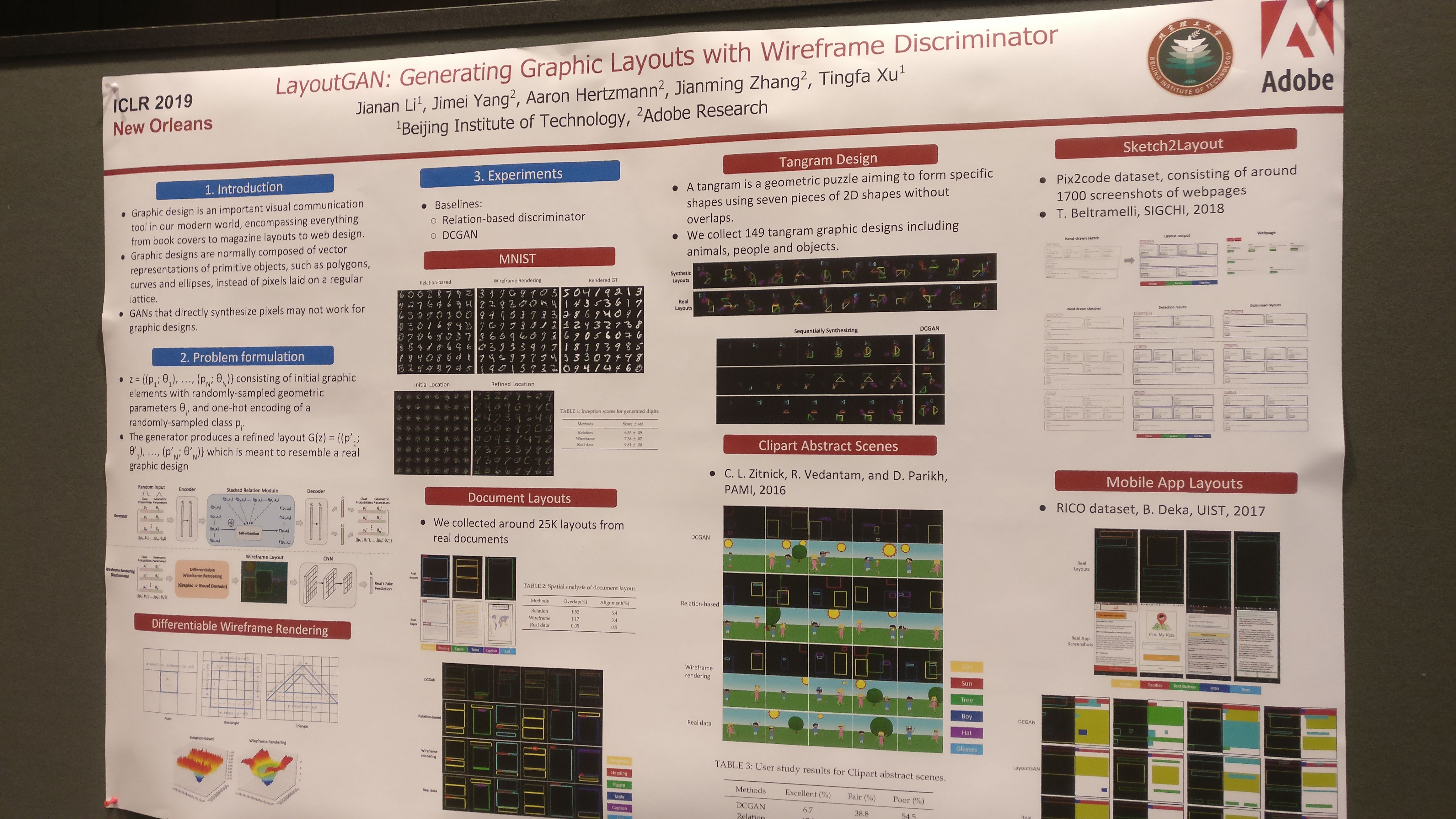
- LayoutGAN: way to generate UI wire-frames using GANs by sensibly composing the different UI elements in a 2D space.
- CompositionalGAN: ways to generate realistic looking compositions by matching different 3D objects and composing them to produce new scenes with realistic lighting and occlusion.
- 3D point cloud generation, Protein backbone generation & Generating labelled graph: these papers are outside of my area of expertise and papers in this broad area featured at ICML 2018 as well, but it is great to see that the work is continuing.
Theme 3: Theoretical advances
As always, there were many papers dealing with some aspect of training (rejection sampling, relativistic GAN, variational discriminator bottleneck) or some theoretical property of generative models (e.g. latent space interpolations or invertibility of GANs).
While academics tend to love this area, at ICML '18, the results were somewhat mixed. I felt that many papers introduced a huge amount of extra complexity to derive some properties that I did not think are hugely interesting or do not expect them to become the de facto standard the same way e.g. Wasserstein GAN or gradient penalties are.
Fortunately, at ICLR that was not the case. All three techniques from above plus averaging during training all look like simple, effective techniques that could easily become the standard pattern for the future state of the art.
Applied Machine Learning
As someone who still frequently has to worry about how I am going to productionize the systems I am building. I was very pleasantly surprised that even the workshop organizers from ICLR thought this was important. So I was trying to capture all the interesting content from the following workshops:
- Reproducibility in ML: this ended up being a pretty useful workshop in the end. As a side note, there only about 7 people when I was there, so I wonder what that says about the state of our field. Generally, I regard reproducibility to be an incredibly important topic, because reproducibility is really the level 0 of understanding how deployed ML systems behave. So all this talk about fairness & bias is almost pointless if we do not get this right.
- Debugging ML: This was a pretty useful workshop, but a lot of the presentations sadly either did not release code or were very academic. I will definitely try to investigate Model Assertions, as the idea makes a lot of sense to me. Overall, debugging again is extremely key for us to ensure that we somewhat understood how the models are building. Everything from adversarial examples to neural nets being able to fit randomly assigned labels are all indicators that we need more tools to understand deep learning.
- Learning from limited labelled data: This is incredibly interesting as little data is a frequent business reality. I was encouraged by the fact that Christopher Re was involved, however, I do not feel that for me there were any particularly strong takeaways.
- Generating highly structured data: Despite Bengio's crowded talk in the beginning, I did not find the oral presentations to be that useful, though I highly recommend checking out the accepted papers.
Conclusion
Overall, I am constantly amazed at the rate of progress of ML and academic conferences have their disadvantages, but if you plan & prepare accordingly, you will get much more of them than any other conference I have ever been to.
TL;DR:
- We generate realistic 512x512 in extreme variety, which leads to further applications.
- GANs seem to be getting more traction in other data types, but the maturity is approx. where images were in 2016.
- Even academics are now thinking more about practical considerations & ML tooling—though they do not always call it that.
Thanks Dr. Daniel Duma and Harpal Singh for their excellent feedback.
GANs & applied ML @ ICLR 2019
TL;DR: at the bottom. I have just return
AI Gets Creative Thanks To GANs Innovations
For an Artificial Intelligence (AI) professional, or data scientist, the barrage of AI-marketing can evoke very different feelings than for a general audience. For one thing, the AI indu
List of ICML GAN Papers
In all seriousness, however, I do respect greatly all the amazing work that the researchers at ICML have presented. I would not be capable of anywhere near their level of work so kudos to them
Comments