...especially about the future
Posted on 14/09/2015 by Jakub Langr
Posted in non-technical
A year has passed since I started to make predictions for this fascinating project run by Philip Tetlock a man that has dedicated about 30 years of his life to understanding geo-political forecasting. Recently the project has ended so I would like to share some insights.
First and foremost, I would love to start with evaluation of my own lessons: I think that overall I ended up over-correcting for the biases I have read about, which is a fascinating lesson. I already mentioned this the first time I was writing about Good Judgment Project (GJP). At least based on my rudimentary understanding the calibration and observation, it seems that normally people have the opposite bias and the curve is flipped around the 45 degree line (the picture below is from the report I received from Good Judgment Project).
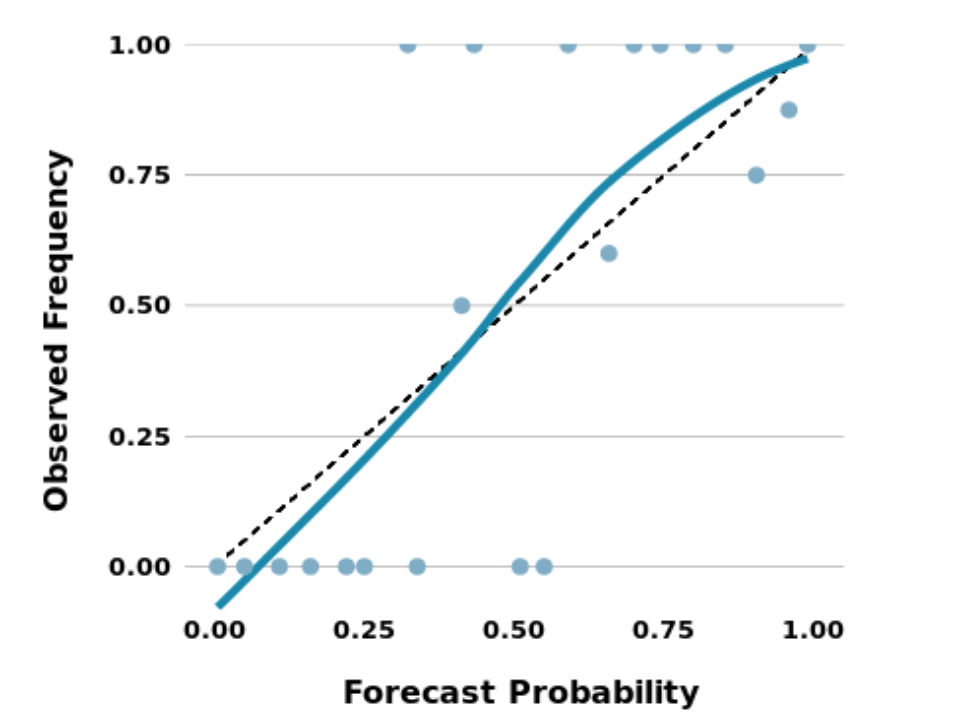
My second point about randomness was just due to my un-rigorous understanding of randomness that I think I now understand: the problem is that something is random given a certain distribution (so we cannot make a better guess than the observed distribution for any particular observation). My third lesson about conditional probability still remains fair, which is: it is difficult to make it correctly, but as Philip Tetlock correctly pointed out, this is the way forward, because it allows us to get exactly the probabilities we care about: if we do X what will the world do? (Because we do not care about if Iran will build a nuclear bomb, we want to know IF we do nothing will Iran build a nuclear bomb?) sting as the project I have been using much during GJP--but they will "soon" be announcing what they are doing next, but who knows what that will entail.
So when the results rolled in they were not too bad, I ended up being the 71st percentile, with my imputed scores dragging me down a little (this was necessary, because you could not answer all the questions, though maybe I also picked questions I understood better).
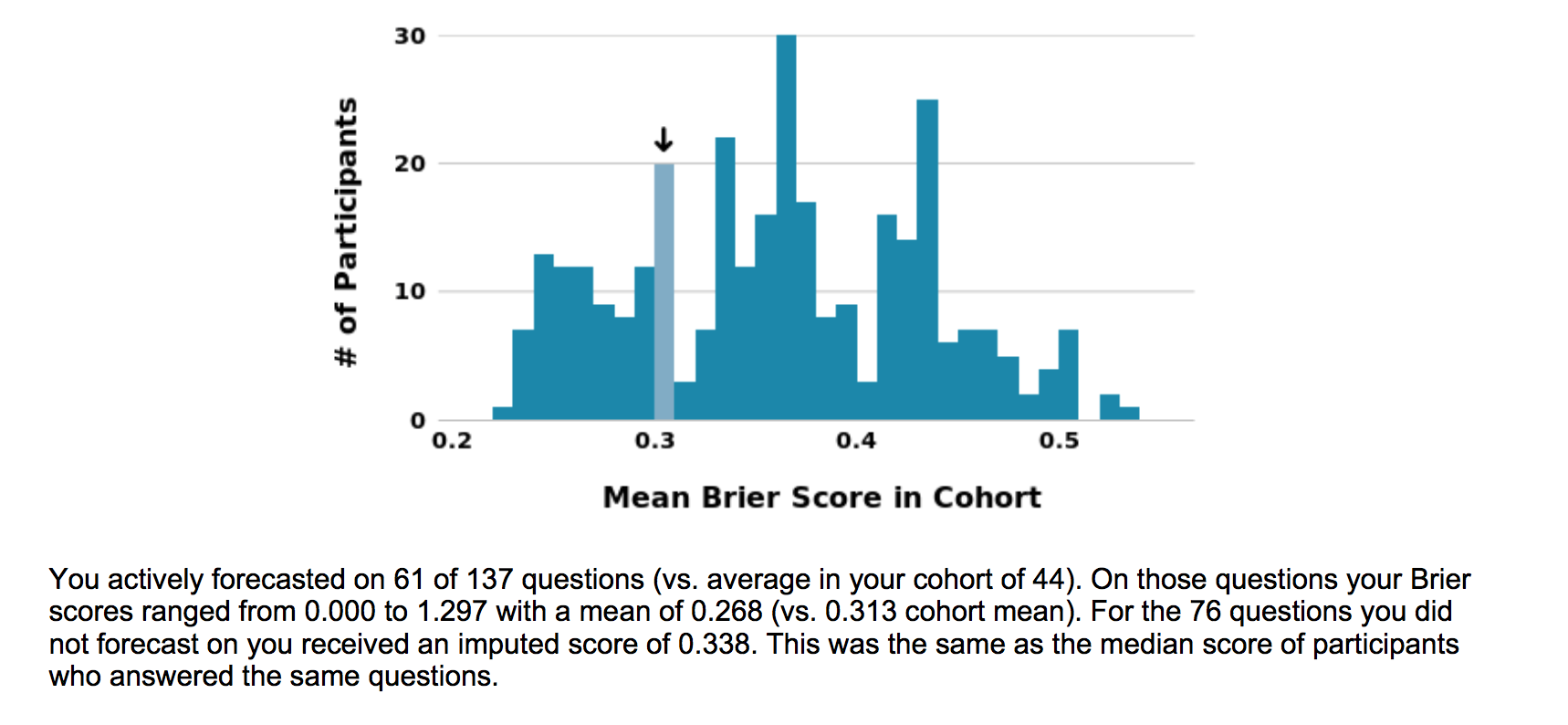
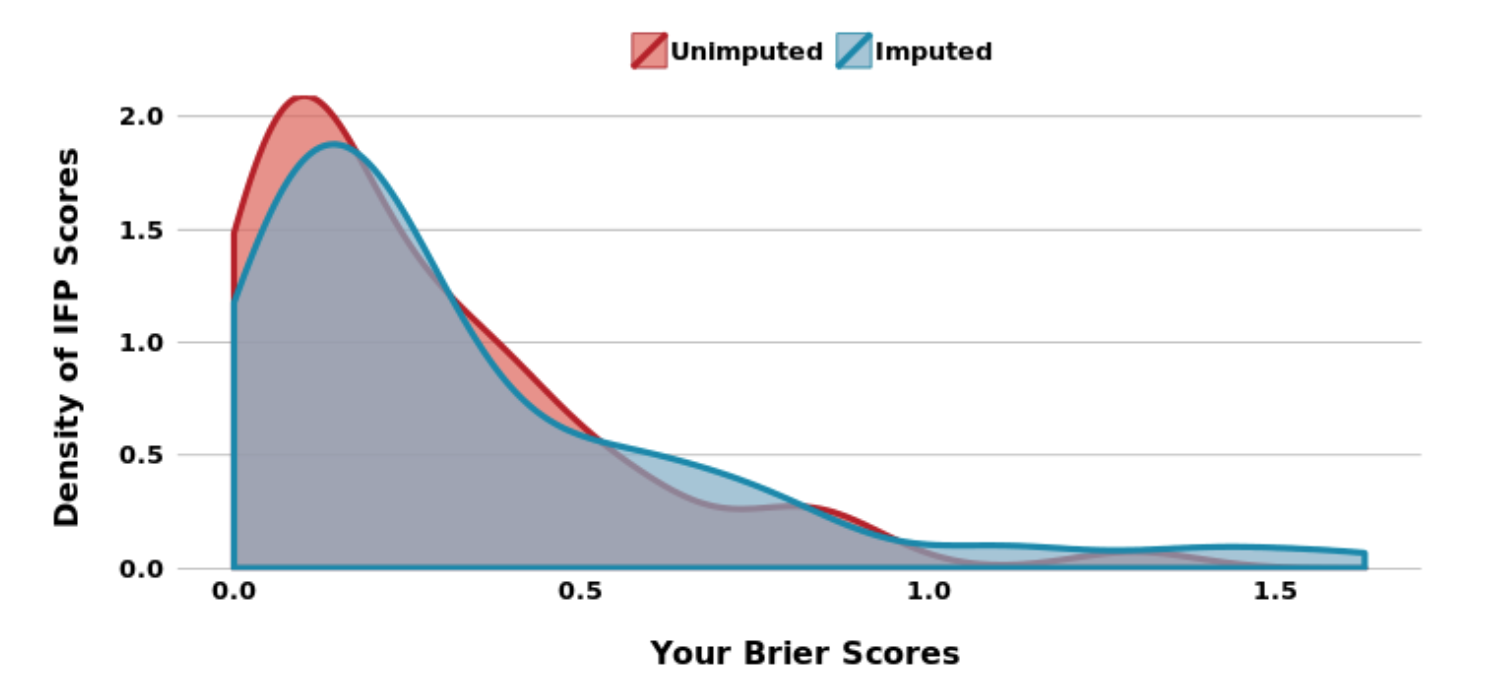
So I think the overall results were quite decent, but I certainly I have loads to learn! While Philip Tetlock certainly tries to help us mere mortals in the the political forecasting by giving us better insight in the Edge online seminar. I have not watched all of them, but they seem amazing so far!
I think what GJP mainly showed me is the power of prediction markets: we can not only use them in companies to guide our own progress, but we can also use them to get a glimpse into the future like Inkling Markets does by pooling our predictions together in a crowd-sourcing manner. This last link is particularly interesting, as I feel this has many commercial applications if only people cared enough about evidence.
Philip Tetlock outlines what are the necessary ingredients of good forecasting and he mentions that the best forecasters tend to be publicly minded software engineers, which is partially supported by the Google information flow study and generally it seems that the more quantitative the subject the better you are likely to be as one political forecasting study finds that the best forecasters in US politics "tend to be liberal and not lawyers" (most of the good ones were economist, interestingly).
But I think there is a potential array of problems: are we not likely to fall into the same illusion as with actual financial markets? E.g. that they are always efficient and therefore we should almost blindly trust them (as seems to be the narrative in the Conservative US politics)? Surely, given that we now know that most people are not better at forecasting than random (though this may be because all of the stastically efficient arbitration has already been done in financial markets by the algorithmic hedge funds). I think this is up for discussion, but I would definitely not try to apply them to policy debates blindly as some authors do:
Prediction markets avoid these problems. There is no question of who the experts are: anyone can invest in a prediction market. There's no question of special interests taking it over; this just distributes free money to more honest investors.
My other problem is that while applications in business are fascinating, the sample sizes with exception of huge (and data-driven?) companies such as Google, there may always be too small of an interest to make this a useful tool.
Perhaps we should just stick to talking to each other for now.
GANs & applied ML @ ICLR 2019
TL;DR: at the bottom. I have just return
AI Gets Creative Thanks To GANs Innovations
For an Artificial Intelligence (AI) professional, or data scientist, the barrage of AI-marketing can evoke very different feelings than for a general audience. For one thing, the AI indu
List of ICML GAN Papers
In all seriousness, however, I do respect greatly all the amazing work that the researchers at ICML have presented. I would not be capable of anywhere near their level of work so kudos to them
Comments