GANs & Semi-Supervised Learning
Posted on 08/04/2017 by Jakub Langr
Posted in technical
In my last blog post we looked what are some of the promising areas in AI and one of the areas that was mentioned many, many times by researchers and my friends as likely future directions of AI, was Generative Adverserial Learning/Networks (GANs). The business appeal is clear: GANs can train from less data, can create fascinating applications (such as 3D model generation) and has lots of future research potential. For more on the practical applications go back to that post.
This post is intended to be somewhat technical and will feature some high-level pseudo-code, but I will try to make it as accessible and hopefully not too boring.
Note that all of this is quite cutting edge and some of the things showcased here were only invented and published in academic journals about a year ago, so this is something that unless you did a post-Doc in some discipline can feel a bit unusual (it did for me) to read things this new. But it also means that there's lots of unmapped theory around this as well as super strange bugs that you have to deal with. But because I recently finished (I just really like taking MOOCs, okay?) the amazing course on Creative Applications of Deep Learning with TensorFlow by the one and the only Parag Mital, I decided to share some of what I have learned.
Semi-supervised learning basically means using labelled (supervised) as well as unlabelled (unsupervised) examples during training and as a concept is quite old. The core idea makes a lot of sense: we have lots of data that in a typical supervised setting lies unused. For example think linear regression on a house price (label) data. We all understand how linear regression can generate house prices, but most houses are not sold, but perhaps we can get the data about them anyways, perhaps from the city planning. This data can give us much better picture, for example about how do different areas compare to each other, where is there a relative shortage of houses and where the biggest houses tend to be. It would be foolish then not to use this data in some way, but traditional algorithms do not allow it.
So Semi-Supervised Learning (SSL) then means using different techniques to somehow add this data to the training of the machine learning (ML) model. But even this is not trivial: if you think of training ML as creating a decision tree and then you can check how good your decision tree was by checking if it got to the correct answer. Unfortunately with the unlabelled data, there's no answer (because the house was not sold during the time the data was gathered), so no learning happens, because the ML algorithm cannot attach correct answer (and therefore loss) to it. I want to focus on one of the techniques in SSL called Generative Adverserial Networks (GANs), which if you read my blog, understand why there's a lot of promise.
GANs work by first having one network create an internal vision of the world (i.e. what do houses look like in general): this is the generative model (G) and basically learns from all the data, because it does not need labels, just all of the features of a typical house in the dataset. The second network, the 'Discriminator' (D), which is the adversary in this case, takes in the examples both from the real dataset and the examples of houses generated by the generator and decides whether this data looks real, the generator has done a good job and gets a smaller loss or...
In other words, imagine now we are trying to label cats or dogs, in this case G will learn how to generate images at first and subsequently get better at making the images more like cats or dogs.
Then we put the G and D to basically compete against each other to produce the best results: hopefully every time G gets better D has to get better to match (though we have to make sure one of them is not too much better than the other). This was one of the core driving principles behind AlphaGo as well. Basically, we get the G to produce images and D to critique them. So G would send an array of images to D and D would output 0 or 1--real or fake back to G. G would then try to come up with better examples based on which fooled D and vice versa. Schematically, it may look something like this:
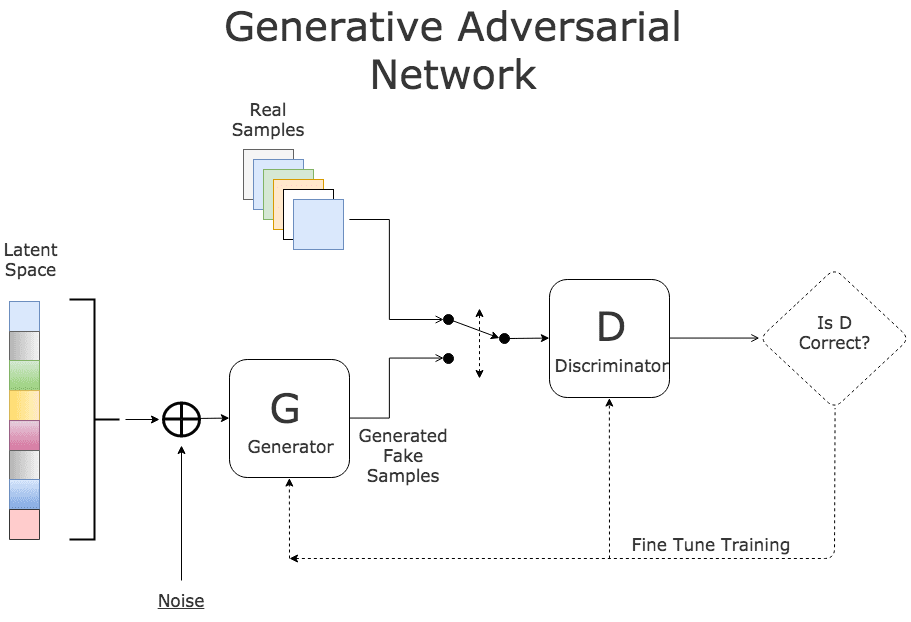
Credit KDNuggets.com
So hopefully it is now clear that we can take lots of unlabelled data, construct a generator and make it learn some of the structure of the data (i.e. what does a typical example look like) then make it compete in making the data that it generates as close to the real data. After this process, we may end up with some pretty decent looking synthetic data and pretty much close to unlimited amount of it. I've skipped lots of caveats, but I will say this: the generator will only be able to generate things alike what it has seen in the data before. Even though it may be easy to forget, this is not magic.

(Those who actually speak Latin forgive me.)
In the highest levels of abstraction this may look something like:
# get data
real_data = pd.read('real_data.csv') # shape (n_examples, n_features+label)
unlabelled_data = pd.read('unlabelled_data.csv') # shape (n_examples, n_features)
# construct the two objects
generator = GeneratorClass()
discriminator = DiscriminatorClass()
# pre-train generator
generator.train(unlabelled_data)
# get synthetic data
synthetic_data = make_compete(generator, discriminator, real_data)
# shape (any_number, n_features)
Okay so a keen reader might observe that we have not described a method for labeling the generated examples. Ideally, what we would like to have is a way of generating examples (e.g. houses with the price attached or pictures of objects with the object description attached). Thankfully for lots of instances, there is a way. If you go back to the diagram, you can see that there's a mention of something called 'the latent space'. Latent space is a way to control what kind of images get generated. If we trained the generator on cats and dogs, one of the dimensions will control how 'catty' or 'doggy' the image will be. It also allows for any interpolation between the two, so you can have a dog-cat or 70% cat, 30% dog. In other words, latent space can be thought of as some seeding factor--you give some initial input to G just so that it does not always generate the same thing, but it turns out this seeding factor has consistent latent ('hidden') properties that certain dimensions can be assigned meaning.
So we can easily modify the pseudocode from above to make this clearer:
# shape (any_number, n_features)
synthetic_cats = make_compete(generator, discriminator,
real_data, input_noise=latent_feature_space.cat)
# shape (any_number, n_features)
synthetic_dogs = make_compete(generator, discriminator,
real_data, input_noise=latent_feature_space.dog)
The amazing thing about this is that in theory, we don't even need to have the data labelled for that task to generate those examples (though it would help a lot). So we could have labelled training data for whether something is a being a good or a bad boy (for both cats and dogs) and we can train the G to create new examples of cats or dogs (based on one parameter of the latent space), both good or bad (based on another parameter of the latent space). Let's say that good or badness of a dog is something we can see from the picture (e.g. it is a bad boy every time it is destroying property, good otherwise). We can then discover parameters in the latent space for both of these features and generate even examples of cat-dog or dog-cat by interpolating between these two values.
Another example is that we can download loads of unlabelled data of faces of celebrities and make the G generate faces and manipulate the latent space so that we get clear examples of male or female and then use it to train another classifier to detect male or female images (with no labelled data of any kind!), which is exactly what I have done. One question that might be still going through your head is 'how do we get this latent space representations of these different attributes?': that, however, is probably beyond the scope of this article unfortunately.
Phew, look at the time: I was hoping to present some actual code so that people can try this on their own, but unfortunately, I felt that this blog post is already long enough so I will leave the code till next time. If there's interest or you would love to see something urgently, drop me a line.
In case you are interested in the actual code, check out the second part of this tutorial.
GANs & applied ML @ ICLR 2019
TL;DR: at the bottom. I have just return
AI Gets Creative Thanks To GANs Innovations
For an Artificial Intelligence (AI) professional, or data scientist, the barrage of AI-marketing can evoke very different feelings than for a general audience. For one thing, the AI indu
List of ICML GAN Papers
In all seriousness, however, I do respect greatly all the amazing work that the researchers at ICML have presented. I would not be capable of anywhere near their level of work so kudos to them
Comments